
Databricks, el servicio de análisis de big data fundado por los desarrolladores originales de Apache Spark, anunció hoy que llevará su proyecto de código abierto Delta Lake para construir lagos de datos a la Fundación Linux y bajo un modelo de gobierno abierto. La compañía anunció el lanzamiento de Delta Lake a principios de este año y, aunque todavía es un proyecto relativamente nuevo, ya ha sido adoptado por muchas organizaciones y ha encontrado el respaldo de compañías como Intel, Alibaba y Booz Allen Hamilton.
"En 2013, tuvimos un pequeño proyecto donde agregamos SQL a Spark en Databricks (…) y lo donó a la Fundación Apache ”, me dijo el CEO y cofundador de Databricks, Ali Ghodsi. "Con el paso de los años, lentamente, la gente ha cambiado la forma en que aprovechan Spark y solo en el último año más o menos, realmente comenzó a darse cuenta de que hay un nuevo patrón que está surgiendo y Spark se está utilizando de una manera completamente diferente de lo que tal vez tuvimos planeado inicialmente ".
Este patrón, dijo, es que las compañías toman todos sus datos y los ponen en lagos de datos y luego hacen un par de cosas con estos datos, el aprendizaje automático y la ciencia de datos son los obvios. Pero también están haciendo cosas que se asocian más tradicionalmente con los almacenes de datos, como la inteligencia empresarial y los informes. El término que Ghodsi usa para este tipo de uso es "Lake House". Cada vez más, Databricks está viendo que Spark se está utilizando para este propósito y no solo para reemplazar a Hadoop y haciendo ETL (extraer, transformar, cargar). "Este tipo de patrones de Lake House que hemos visto emerger cada vez más y queríamos duplicarlo".
 Spark 3.0, que se está lanzando hoy, habilita más de estos casos de uso y los acelera significativamente, además del lanzamiento de una nueva característica que le permite agregar un catálogo de datos conectables a Spark.
Spark 3.0, que se está lanzando hoy, habilita más de estos casos de uso y los acelera significativamente, además del lanzamiento de una nueva característica que le permite agregar un catálogo de datos conectables a Spark.
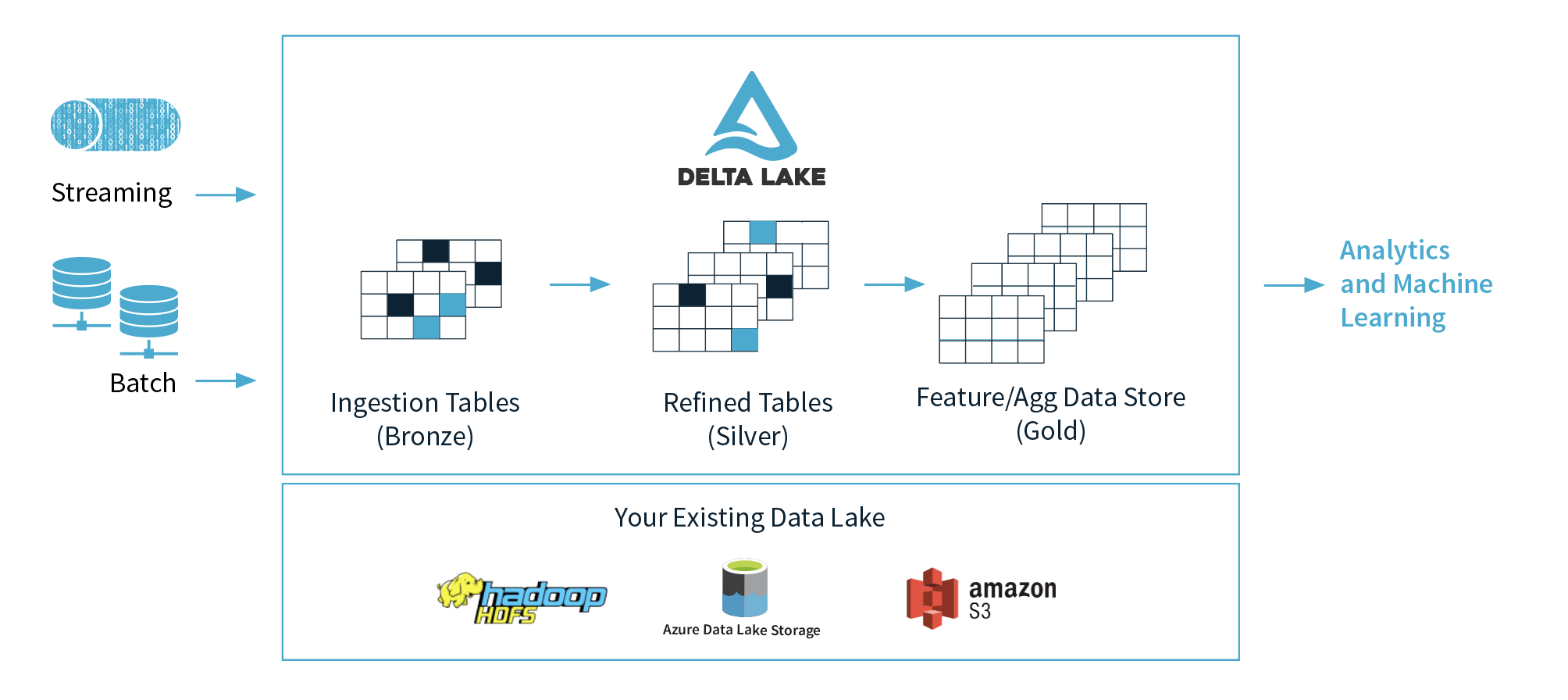
Data Lake, dijo Ghodsi, es esencialmente la capa de datos del patrón de Lake House. Brinda soporte para transacciones ACID a lagos de datos, manejo escalable de metadatos y versiones de datos, por ejemplo. Todos los datos se almacenan en el formato Apache Parquet y los usuarios pueden aplicar esquemas (y cambiarlos con relativa facilidad si es necesario).
Es interesante ver a Databricks elegir la Fundación Linux para este proyecto, dado que sus raíces están en la Fundación Apache. "Estamos muy emocionados de asociarnos con ellos", dijo Ghodsi sobre por qué la compañía eligió la Fundación Linux. “Dirigen los proyectos más grandes del planeta, incluido el proyecto Linux, pero también muchos proyectos en la nube. Todo lo relacionado con la nube está en la Fundación Linux ".
"Traer Delta Lake al hogar neutral de la Fundación Linux ayudará a la comunidad de código abierto que depende del proyecto a desarrollar la tecnología que aborde cómo se almacenan y procesan los grandes datos, tanto en las instalaciones como en la nube", dijo Michael Dolan, vicepresidente de Programas Estratégicos en la Fundación Linux. "La Fundación Linux ayuda a las comunidades de código abierto a aprovechar un modelo de gobierno abierto para permitir una amplia contribución de la industria y la creación de consenso, lo que mejorará el estado del arte para el almacenamiento de datos y la confiabilidad".