


Facebook Las herramientas de IA son lo único que se interpone entre sus usuarios y la creciente avalancha de odio y desinformación que está experimentando la plataforma. Los investigadores de la compañía han desarrollado algunas capacidades nuevas para los sistemas que mantienen a raya al adversario, identificando información errónea relacionada con COVID-19 y discursos de odio disfrazados de memes.
La detección y eliminación de información errónea relacionada con el virus es obviamente una prioridad en este momento, ya que Facebook y otras redes sociales se convierten en un caldo de cultivo no solo para la especulación y discusión ordinarias, sino también para la interferencia maliciosa de campañas organizadas con el objetivo de sembrar la discordia y difundir la pseudociencia.
“Hemos visto un gran cambio en el comportamiento en todo el sitio debido a COVID-19, un gran aumento en la información errónea que consideramos peligroso”, dijo el CTO de Facebook Mike Schroepfer en una llamada con la prensa el día de hoy.
La compañía tiene contratos con docenas de organizaciones de verificación de hechos en todo el mundo, pero, dejando de lado la cuestión de cuán efectivas son realmente las colaboraciones, la desinformación tiene una forma de mutar rápidamente, lo que hace que eliminar una sola imagen o vincular un asunto complejo.
Eche un vistazo a las tres imágenes de ejemplo a continuación, por ejemplo:

Un algoritmo de visión por computadora poco sofisticado calificaría estas imágenes como imágenes completamente diferentes debido a esos pequeños cambios (dan como resultado diferentes hashes) o de todos modos debido a una similitud visual abrumadora. Por supuesto, vemos las diferencias de inmediato, pero entrenar un algoritmo para hacerlo de manera confiable es muy difícil. Y la forma en que las cosas se propagan en Facebook, puede terminar con miles de variaciones en lugar de un puñado.
“Lo que queremos poder hacer es detectar esas cosas como idénticas porque, para una persona, son lo mismo”, dijo Schroepfer. “Nuestros sistemas anteriores eran muy precisos, pero eran muy frágiles y frágiles incluso con cambios muy pequeños. Si cambia una pequeña cantidad de píxeles, estábamos demasiado nerviosos de que fuera diferente, por lo que lo marcaríamos como diferente y no lo eliminaríamos. Lo que hicimos aquí durante los últimos dos años y medio es construir un detector de similitud basado en redes neuronales que nos permitió capturar mejor una variedad más amplia de estas variantes nuevamente con una precisión muy alta “.
Afortunadamente, analizar imágenes a esas escalas es una especialidad de Facebook. La infraestructura está ahí para comparar fotos y buscar características como caras y cosas menos deseables; Solo necesitaba que se le enseñara qué buscar. El resultado, después de años de trabajo, debería decirse, es SimSearchNet, un sistema dedicado a encontrar y analizar casi duplicados de una imagen dada mediante una inspección minuciosa de sus características más destacadas (que pueden no ser lo que usted o yo haríamos) aviso).
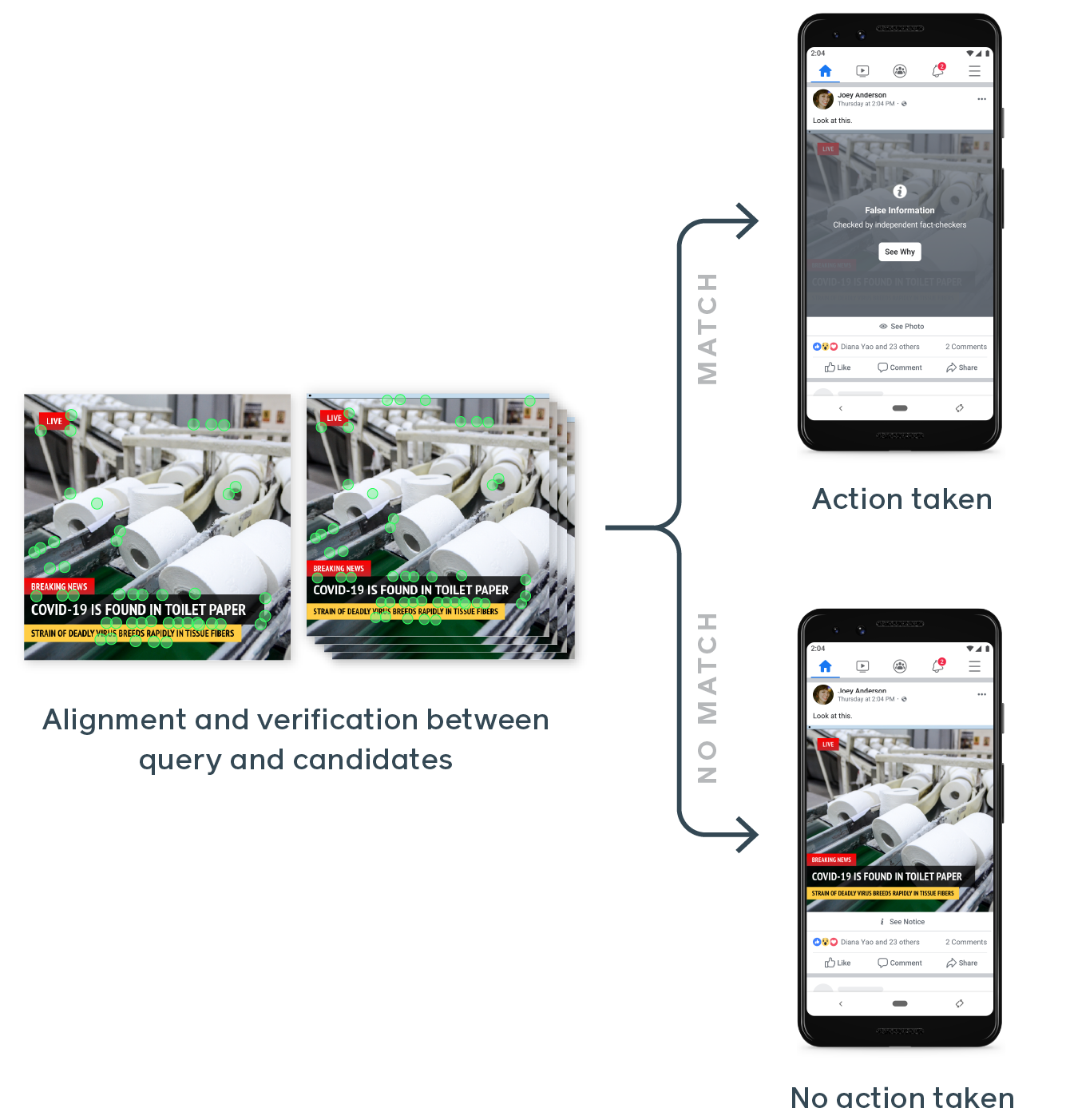

SimSearchNet está inspeccionando actualmente cada imagen cargada en Instagram y Facebook, miles de millones por día.
El sistema también está monitoreando Facebook Marketplace, donde las personas que intentan eludir las reglas subirán la misma imagen de un artículo a la venta (por ejemplo, una máscara facial N95) pero ligeramente editada para evitar que el sistema la marque como no permitida. Con el nuevo sistema, se observan las similitudes entre las fotos actualizadas o editadas y la venta se detiene.
Memes odiosos y zorrillos ambiguos
Otro problema con el que Facebook ha estado lidiando es el discurso de odio, y su hermano más vagamente definido odioso habla. Sin embargo, un área que ha resultado especialmente difícil para los sistemas automatizados son los memes.
El problema es que el significado de estas publicaciones a menudo resulta de una interacción entre la imagen y el texto. Las palabras que serían perfectamente apropiadas o ambiguas por sí mismas tienen su significado aclarado por la imagen en la que aparecen. No solo eso, sino que hay un sinfín de variaciones en las imágenes o frases que pueden cambiar sutilmente (o no cambiar) el significado resultante. Vea abajo:


Para ser claros, estos son “memes malos” atenuados, no el tipo de odio que a menudo se encuentra en Facebook.
Cada pieza individual del rompecabezas está bien en algunos contextos, insultante en otros. ¿Cómo puede un sistema de aprendizaje automático aprender a decir qué es bueno y qué es malo? Este “discurso de odio multimodal” es un problema no trivial debido a la forma en que funciona la IA. Hemos creado sistemas para comprender el lenguaje y clasificar las imágenes, pero cómo se relacionan esas dos cosas no es un problema tan simple.
Los investigadores de Facebook señalan que hay “sorprendentemente poca” investigación sobre el tema, por lo que la suya es más una misión exploratoria que una solución. La técnica a la que llegaron tenía varios pasos. Primero, hicieron que los humanos anotaran una gran colección de imágenes de tipo meme como odiosas o no, creando el conjunto de datos Hateful Memes. A continuación, se capacitó un sistema de aprendizaje automático sobre estos datos, pero con una diferencia crucial con respecto a los existentes.
Casi todos estos algoritmos de análisis de imágenes, cuando se presentan con texto y una imagen al mismo tiempo, clasificarán uno, luego el otro, y luego intentarán relacionar los dos. Pero eso tiene la debilidad antes mencionada de que, independientemente del contexto, el texto y las imágenes de memes odiosos pueden ser totalmente benignos.
El sistema de Facebook combina la información del texto y la imagen anteriormente en la tubería, en lo que llama “fusión temprana” para diferenciarla del enfoque tradicional de “fusión tardía”. Esto es más parecido a cómo lo hace la gente: ver todos los componentes de un medio de comunicación antes de evaluar su significado o tono.
En este momento, los algoritmos resultantes no están listos para la implementación en general, con una precisión general de alrededor del 65-70 por ciento, aunque Schroepfer advirtió que el equipo usa “el más difícil de los problemas difíciles” para evaluar la eficacia. Algunos discursos de odio multimodales serán triviales para marcar como tales, mientras que algunos son difíciles de medir incluso para los humanos.
Para ayudar a avanzar en el arte, Facebook está llevando a cabo un “Desafío de Memes Odiosos” como parte de la conferencia NeurIPS AI a finales de este año; Esto se hace comúnmente con tareas difíciles de aprendizaje automático, ya que los nuevos problemas como este son como la hierba gatera para los investigadores.
El papel cambiante de AI en la política de Facebook
Facebook anunció sus planes de confiar más en la IA para la moderación en los primeros días de la crisis COVID-19. En una llamada de prensa en marzo, Mark Zuckerberg dijo que la compañía esperaba más “falsos positivos”, instancias de contenido marcado cuando no debería ser, con la flota de 15,000 contratistas de moderación de la compañía en casa con licencia pagada.
YouTube y Twitter también transfirieron más de su moderación de contenido a AI al mismo tiempo, emitiendo advertencias similares sobre cómo una mayor dependencia de la moderación automatizada podría conducir a contenido que en realidad no infringe las reglas de la plataforma que se marcan por error.
A pesar de sus esfuerzos de inteligencia artificial, Facebook ha estado ansioso por que sus revisores de contenido humano vuelvan a la oficina. A mediados de abril, Zuckerberg dio un cronograma de cuándo se podía esperar que los empleados volvieran a la oficina, señalando que los revisores de contenido ocupaban un lugar destacado en la lista de “empleados críticos” de Facebook marcada para el retorno más temprano.
Si bien Facebook advirtió que sus sistemas de inteligencia artificial podrían eliminar el contenido de manera demasiado agresiva, el discurso de odio, las amenazas violentas y la información errónea continúan proliferando en la plataforma a medida que la crisis del coronavirus continúa. Facebook fue criticado recientemente por difundir un video viral que desalienta a las personas a usar máscaras faciales o a buscar vacunas una vez que están disponibles, una clara violación de las reglas de la plataforma contra la información errónea sobre la salud.
El video, un extracto de un próximo pseudo-documental llamado “Plandemic”, inicialmente despegó en YouTube, pero los investigadores descubrieron que el próspero ecosistema de grupos conspiracionistas de Facebook lo compartía a lo largo y ancho de la plataforma, inyectándolo en un discurso en línea convencional. El video de 26 minutos de duración, salpicado de conspiraciones, también es un ejemplo perfecto del tipo de contenido que un algoritmo tendría dificultades para entender.
El martes, Facebook también publicó un informe de aplicación de normas comunitarias que detalla sus esfuerzos de moderación en categorías como terrorismo, acoso y discurso de odio. Si bien los resultados solo incluyen un período de un mes durante la pandemia, podemos esperar ver más del impacto del cambio de Facebook a la moderación de la IA la próxima vez.
En una llamada sobre los esfuerzos de moderación de la compañía, Zuckerberg señaló que la pandemia ha hecho que “la parte de revisión humana” de su moderación sea mucho más difícil, ya que las preocupaciones sobre la protección de la privacidad del usuario y la salud mental de los trabajadores hacen que el trabajo a distancia sea un desafío para los revisores, pero uno es la compañía está navegando ahora. Facebook confirmó a TechCrunch que la compañía ahora está permitiendo que una pequeña parte de los revisores de contenido de tiempo completo regresen a la oficina de forma voluntaria y, según el Vicepresidente de Integridad de Facebook, Guy Rosen, “la mayoría” de los revisores de contenido del contrato ahora pueden trabajar desde casa. “Los humanos continuarán siendo una parte muy importante de la ecuación”, dijo Rosen.