

Biblioteca del Congreso/Navegador de Periódicos
- Un informático de la Biblioteca del Congreso está utilizando el aprendizaje automático para aislar imágenes históricas de los archivos de periódicos digitales.
- El proyecto, denominado Newspaper Navigator, utiliza algoritmos ópticos de reconocimiento de caracteres para convertir caracteres escritos a mano o basados en texto en un documento de búsqueda. El aprendizaje automático automatiza el proceso.
- Puede leer el documento de preimpresión del equipo (lo que significa que aún no se ha revisado por pares), publicado en el servidor Arxiv el 4 de mayo.
En julio de 1848, L’ilustración, un semanario francés, imprimió la primera foto que aparece junto a una historia. Representaba barricadas parisinas establecidas durante el levantamiento de los Días de Junio de la ciudad. Casi dos siglos después, el fotoperiodismo ha otorgado bibliotecas con legiones de imágenes de archivo que cuentan historias de nuestro pasado. Pero sin un enfoque metódico para curarlos, estas imágenes históricas podrían perderse en montículos interminables de datos.
Es por eso que la Biblioteca del Congreso en Washington, D.C. está siendo experimentada. Los investigadores están utilizando algoritmos especializados para extraer imágenes históricas de los periódicos. Aunque los escaneos digitales ya pueden compilar fotos, estos algoritmos también pueden analizar, Y archivarlos. Eso ha dado lugar a 16 millones de páginas de periódicos en imágenes que los archiveros pueden tamizar con una simple búsqueda.

La Biblioteca de Arte Bridgeman
Ben Lee, innovador en residencia en la Biblioteca del Congreso, y un estudiante graduado que estudia ciencias de la computación en la Universidad de Washington, está encabezando lo que se llama Navegador de periódicos. Su conjunto de datos proviene de un proyecto existente llamado Chronicling America, que recopila páginas de periódicos digitales entre 1789 y 1963.
Se dio cuenta de que la biblioteca ya se había embarcado en un viaje de crowdsourcing para convertir algunas de esas páginas de periódicos en una base de datos de búsqueda, con un enfoque en el contenido relacionado con la Primera Guerra Mundial. Los voluntarios podrían marcar y transcribir las páginas de los periódicos digitales, algo en lo que las computadoras no siempre son tan geniales. En efecto, lo que habían construido era un conjunto perfecto de datos de entrenamiento para un algoritmo de aprendizaje automático que podía automatizar todo ese trabajo agotador y laborioso.
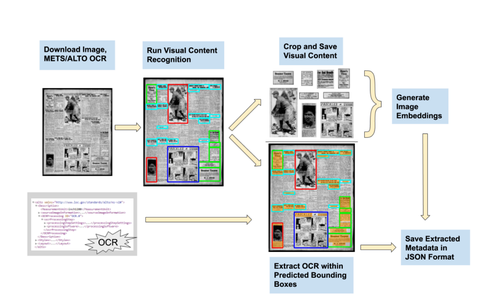
“A los voluntarios se les pidió que dibujaran las cajas delimitadoras de tal manera que incluyeras cosas como títulos y subtítulos, y entonces el sistema… identificar ese texto”, dice Lee Mecánica Popular. “Pensé, vamos a tratar de ver cómo podemos usar algunas herramientas de informática emergentes para aumentar nuestras habilidades y cómo usamos las colecciones”.
En total, el sistema tardó unos 19 días en procesar el tiempo para tamizar las 16.358.041 páginas de periódicos. De ellos, el sistema sólo no pudo procesar 383 páginas.
¿Qué es el reconocimiento óptico de caracteres?
Navegador de periódicos/ArXiv
Newspaper Navigator se basa en la misma tecnología que los ingenieros utilizaron para crear Google Books. Se llama reconocimiento óptico de caracteres, u OCR para abreviar, y es una clase de algoritmos de aprendizaje automático que pueden traducir imágenes de símbolos escritos a mano o escritos a mano, como palabras en una página de revista escaneada, en texto digital legible por máquina.
En Mecánica Popular, tenemos un archivo de casi todas nuestras revistas en Google Books, que data de enero de 1905. Debido a que Google ha utilizado OCR para optimizar esos escaneos digitales, es fácil pasar y buscar en todo nuestro archivo para obtener menciones de, digamos, “espías”, para obtener un resultado como este:

Pero las imágenes son otra cosa.
Utilizando el aprendizaje profundo, Lee construyó un modelo de detección de objetos que podía aislar siete tipos diferentes de contenido: fotografías, ilustraciones, mapas, cómics, dibujos animados editoriales, titulares y anuncios. Así que si quieres encontrar fotos específicamente de soldados en trincheras, puedes buscar “trenches” en Newspaper Navigator y obtener resultados al instante.
Antes, tendrías que tamizar a través de miles de páginas de datos. Este avance será extremadamente poderoso para los archivistas, y Lee ha abierto todo el código que utilizó para construir su modelo de aprendizaje profundo.
“Nuestra esperanza es que las personas que tienen colecciones de periódicos… podría ser capaz de usar el código que estoy lanzando, o hacer su propia versión de esto a diferentes escalas”, dice Lee. Un día, su biblioteca local podría usar este tipo de tecnología para ayudar a digitalizar y archivar la historia de su comunidad local.
¿Bibliotecas del Futuro?

Esto no quiere decir que el sistema sea perfecto. “Definitivamente hay casos en los que el sistema se catasiará especialmente, una ilustración como una caricatura o algo así”, dice Lee. Pero ha dado cuenta de estos falsos positivos a través de puntuaciones de confianza que ponen de relieve la probabilidad de que una determinada pieza de medios de comunicación sea una caricatura o una fotografía.
Lee también dice que, a pesar de sus mejores esfuerzos, este tipo de sistemas siempre codificarán algún sesgo humano. Pero para reducir cualquier mano dura, Lee trató de centrarse en enfatizar las clases de imágenes ,dibujos animados versus anuncios— en lugar de lo que realmente se muestra en las imágenes en sí. Lee cree que esto debería reducir las instancias del sistema que intentan hacer llamadas de juicio sobre el conjunto de datos. Eso debería dejarse en el centro del curator, dice.
“Creo que muchas de estas preguntas son muy importantes a considerar y uno de mis objetivos es utilizar este proyecto como una oportunidad para resaltar algunos de los problemas relacionados con el sesgo algorítmico”, dice Lee. “Es fácil suponer que el aprendizaje automático resuelve todos los problemas, eso es una fantasía, pero en este proyecto, creo que es una oportunidad real para enfatizar que tenemos que tener cuidado con la forma en que usamos estas herramientas”.
Este contenido es creado y mantenido por un tercero e importado en esta página para ayudar a los usuarios a proporcionar sus direcciones de correo electrónico. Es posible que pueda encontrar más información sobre este contenido y contenido similar en piano.io
Esta sección de comentarios es creada y mantenida por un tercero e importada en esta página. Es posible que pueda encontrar más información en su sitio web.