Muchas empresas y municipalidades tienen cientos o miles de horas de video y formas limitadas de convertirlo en datos utilizables. Voxel51 ofrece una opción basada en el aprendizaje automático que mastica el video y lo etiqueta, no solo con el simple reconocimiento de imagen sino también con la comprensión de los movimientos y los objetos a lo largo del tiempo.
Anotar videos es una tarea importante para muchas industrias, la más conocida es la conducción autónoma. Pero también es importante en la robótica, las industrias de servicios y minoristas, para los encuentros con la policía (ahora que las cámaras corporales se están volviendo comunes), y así sucesivamente.
Se realiza de varias maneras, desde humanos dibujando literalmente cuadros alrededor de objetos en cada cuadro y escribiendo lo que contiene hasta enfoques más avanzados que automatizan gran parte del proceso, incluso en tiempo real. Pero la regla general con estos es que se hacen cuadro por cuadro.
Un solo cuadro es excelente si desea saber cuántos automóviles hay en una imagen, si hay una señal de alto o qué lee una placa. Pero, ¿qué pasa si necesita saber si alguien está caminando o saliendo del camino? ¿Qué pasa si alguien está saludando o tirando una piedra? ¿Las personas en una multitud van hacia la derecha o hacia la izquierda, en general? Este tipo de cosas es difícil de inferir a partir de un solo cuadro, pero mirar solo dos o tres sucesivamente lo deja claro.
Ese hecho es lo que la startup Voxel51 está aprovechando para enfrentar la competencia establecida en este espacio. Los algoritmos nativos de video pueden hacer algunas cosas que los de un solo cuadro no pueden, y donde se superponen, los primeros a menudo lo hacen mejor.
Voxel51 surgió del trabajo de visión por computadora realizado por sus cofundadores, CEO Jason Corso y CTO Brian Moore, en la Universidad de Michigan. Este último tomó la clase de visión por computadora del primero y, finalmente, los dos descubrieron que compartían el deseo de sacar ideas del laboratorio.
“Comencé la compañía porque tenía esta gran cantidad de investigación”, dijo Corso, “y la gran mayoría de los servicios disponibles estaban enfocados en la comprensión basada en imágenes en lugar de la comprensión basada en video. Y en casi todos los casos que hemos visto, cuando usamos un modelo basado en video vemos mejoras de precisión “.
Si bien cualquier antiguo algoritmo estándar puede reconocer un automóvil o una persona en una imagen, se necesita mucho más conocimiento para hacer algo que pueda, por ejemplo, identificar comportamientos de fusión en una intersección o determinar si alguien se ha deslizado entre los automóviles para ir al paseo . En cada una de esas situaciones, el contexto es importante y se necesitan múltiples cuadros de video para caracterizar la acción.
“Cuando procesamos datos, observamos el volumen espacio-temporal como un todo”, dijo Corso. “Cinco, diez, treinta cuadros … nuestros modelos calculan qué tan atrás y hacia adelante debería verse para encontrar una inferencia robusta”.
En otras palabras, más normales, el modelo de IA no es solo mirar una imagen, sino relaciones entre muchas imágenes a lo largo del tiempo. Si no está muy seguro de si una persona en un cuadro determinado se agacha o aterriza de un salto, sabe que puede desplazarse un poco hacia adelante o hacia atrás para encontrar la información que lo aclarará.
E incluso para tareas de inferencia más comunes, como contar los autos en la calle, esos datos pueden verificarse o actualizarse al mirar hacia atrás o saltar hacia adelante. Si solo puedes ver cinco autos porque uno es grande y bloquea un sexto, eso no cambia el hecho de que hay seis autos. Incluso si cada cuadro no muestra todos los automóviles, sigue siendo importante, por ejemplo, para un sistema de monitoreo de tráfico.
La objeción natural a esto es que procesar 10 fotogramas para descubrir lo que una persona está haciendo es más costoso, computacionalmente hablando, que procesar un solo fotograma. Eso es cierto si lo trata como una serie de imágenes fijas, pero no es así como lo hace Voxel51.

“Nos salimos con la suya al procesar menos píxeles por cuadro”, explicó Corso. “La cantidad total de píxeles que procesamos podría ser igual o menor que un solo cuadro, dependiendo de lo que queramos que haga”.
Por ejemplo, en un video que necesita ser examinado de cerca, pero la velocidad no es una preocupación (como una acumulación de datos de cámaras de tráfico), puede pasar todo el tiempo que necesita en cada cuadro. Pero para un caso en el que el cambio debe ser más rápido, puede hacer un pase rápido y en tiempo real para identificar objetos y movimientos principales, luego volver a enfocarse en las partes que son más importantes, no en el cielo inmóvil o estacionado automóviles, pero personas y otros objetos conocidos.
La plataforma está altamente parametrizada y, naturalmente, no comparte las limitaciones de las anotaciones impulsadas por humanos (aunque esta última sigue siendo la opción principal para aplicaciones altamente novedosas en las que tendría que construir un modelo desde cero).
“No tiene que preocuparse, es el anotador A o el anotador B, y nuestra plataforma es una plataforma de cómputo, por lo que se adapta a la demanda”, dijo Corso.
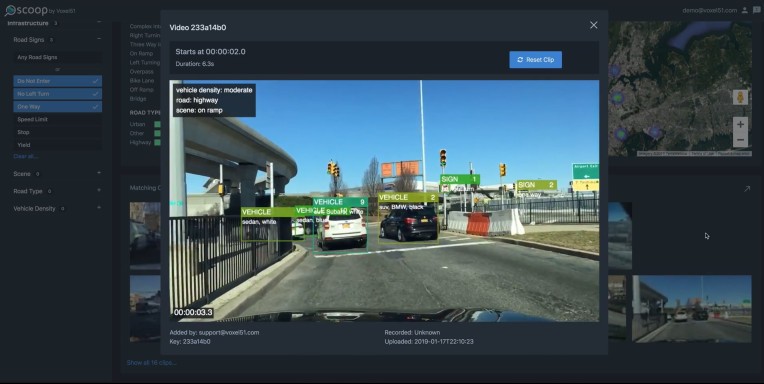
Han empaquetado todo en una interfaz de arrastrar y soltar que llaman Scoop. Dejas caer tus datos (videos, GPS, cosas así) y dejas que el sistema se alimente a través de ellos. Luego tiene un mapa navegable que le permite enumerar o rastrear cualquier cantidad de cosas: tipos de letreros, BMW azules, Toyotas rojos, carriles de giro a la derecha solamente, personas que caminan por la acera, personas que se apiñan en un cruce de peatones, etc. Y usted puede combine categorías, en caso de que esté buscando escenas en las que ese BMW azul estaba en un carril de solo giro a la derecha.

Cada avistamiento se adjunta al video de origen, con cuadros delimitadores sobre él que indican las ubicaciones de lo que está buscando. Luego puede exportar los videos relacionados, con o sin anotaciones. Hay un sitio de demostración que muestra cómo funciona todo.
No es un poco como los mapas en vivo recientemente anunciados por Nexar, aunque obviamente también es bastante diferente. El hecho de que dos compañías puedan perseguir el procesamiento impulsado por IA de cantidades masivas de datos de video a nivel de calle y seguir siendo propuestas comerciales distintas indica cuán grande es el mercado potencial para este tipo de servicio.
A pesar de su inteligencia de las características de la calle, Voxel51 no persigue los autos sin conductor para comenzar. Las empresas en ese espacio, como Waymo y Toyota, están buscando sistemas bastante estrechos, orientados verticalmente y altamente enfocados en identificar objetos y comportamientos específicos de la navegación autónoma. Las prioridades y necesidades son diferentes de, por ejemplo, una empresa de seguridad o una fuerza policial que monitorea cientos de cámaras a la vez, y ahí es donde se dirige la compañía en este momento. Eso es consistente con el financiamiento previo a la producción de la compañía, que provino de una subvención del NIST en el sector de seguridad pública.

Construido sin intervención humana a partir de 250 horas de video, un mapa de señales / señales como este sería útil para muchos municipios.
“La primera fase de ir al mercado se centra en las ciudades inteligentes y la seguridad pública”, dijo Corso. “Estamos trabajando con departamentos de policía centrados en la seguridad ciudadana. Entonces los oficiales quieren saber, ¿hay un incendio estallando, o hay una multitud reuniéndose donde no debería estar reuniéndose? “
“En este momento es un piloto experimental: nuestro sistema funciona junto con el Citiwatch de Baltimore”, continuó, refiriéndose a un sistema de vigilancia de vigilancia del crimen en la ciudad. “Tienen 800 cámaras y cinco o seis policías retirados que se sientan en un sótano a verlos, por lo que les ayudamos a ver la alimentación correcta en el momento correcto. La retroalimentación ha sido emocionante: cuando [Citiwatch overseer Major Hood] vio la salida de nuestro modelo, no solo la persona sino el comportamiento, discutiendo o peleando, sus ojos se iluminaron “.
Ahora, seamos honestos: suena un poco distópico, ¿no? Pero Corso fue cuidadoso al notar que no están en el negocio de rastrear individuos.
“Estamos principalmente analíticos de video que preservan la privacidad; No tenemos capacidad ni interés en ejecutar la identificación de rostros. No nos centramos en ningún tipo de identidad “, dijo.
Es bueno que la prioridad no esté en la identidad, pero todavía es un poco aterrador estar disponible. Y, sin embargo, como cualquiera puede ver, la capacidad está ahí: solo es cuestión de hacerlo útil y útil en lugar de simplemente espeluznante. Si bien uno puede imaginar usos poco éticos como tomar medidas enérgicas contra los manifestantes, también es fácil imaginar cuán útil podría ser esto en una situación de alerta Amber o Silver. ¿Chico malo con un Lexus beige? Boom, visto por última vez aquí.
En cualquier caso, la plataforma es impresionante y el trabajo de visión por computadora que se utilizó aún más. No sorprende que la compañía haya recaudado un poco de efectivo para avanzar. La ronda de semillas de $ 2 millones fue dirigida por eLab Ventures, una firma de capital de riesgo con sede en Palo Alto y Ann Arbor, y la compañía atrajo anteriormente la subvención de $ 1.25 millones de NIST mencionada anteriormente.
El dinero se utilizará para los fines esperados, establecer el producto, desarrollar el soporte y el lado no técnico de la empresa, y así sucesivamente. Los precios flexibles y los resultados casi instantáneos (en términos de procesamiento de video) parecen algo que impulsará la adopción bastante rápido dados los enormes volúmenes de video sin explotar que existen. Espere ver más compañías como Corso y Moore, ya que el valor de ese video se vuelve claro.