
En septiembre de 2020, un estudiante de la Universidad de Victoria (Canadá) descubrió sin querer que Twitter destacaba más los rostros blancos al recortar las imágenes. Su hilo de tuits provocó una gran polémica y decenas de pruebas de otros tuiteros en el mismo sentido. Finalmente Twitter decidió ver qué pasaba. El proceso ha culminado este mes de agosto con una competición ―la primera de este tipo― entre informáticos a quienes se permitió analizar el algoritmo. Y se les ofreció una recompensa por sus hallazgos. El concurso confirmó que algún sesgo existía. El vencedor, el doctorando de la Universidad Politécnica de Lausane (Suiza) Bogdan Kulynych (Ucrania, 1993) ha descubierto que ciertamente el algoritmo prefiere rostros claros, jóvenes, delgados y con rasgos femeninos.
El sesgo de los algoritmos no es nada nuevo. Un algoritmo de este tipo es un programa que ordena resultados a partir de datos que se le proporcionan. En el caso de Twitter escogía el fragmento (los píxeles) de una imagen que creía que iba a ser más interesante para destacarlo y que los usuarios de Twitter lo vieran en sus pantallas.
Este algoritmo proviene de un modelo elaborado a partir de seguir la mirada humana cuando aparece una imagen en una pantalla. Y supuestamente los humanos prefieren caras de piel clara, femeninas, delgadas, jóvenes, y con un tono cálido y bien contrastado. En un estudio previo al concurso que hizo la propia red social, y en el que ya se veía cierto sesgo, también analizaron lo que llaman la “mirada masculina”: a veces el algoritmo se centraba en zonas del cuerpo femenino que no eran la cara, lo que, según el artículo científico, se originaba en “la representación constante de las mujeres como objetos sexuales para el placer desde la perspectiva de los hombres heterosexuales”.
“En mi investigación generé varias caras artificiales y las modifiqué no arbitrariamente, sino de una manera muy específica para ver en cuáles el algoritmo incrementaba la prominencia”, explica Kulynych a EL PAÍS en una conversación por videoconferencia. Es decir, que cuando hacía un recorte automático, tendía a conservar o a destacar más dichos rostros. “Seleccioné solo un pequeño grupo de 16 caras por problemas de tiempo y porque el proceso computacional es largo. Eran caras diversas y al final vi patrones. El algoritmo daba más prominencia a caras más jóvenes, delgadas, con más calidez y rasgos femeninos”, continúa.
Aunque la muestra de Kulynych es pequeña porque la competición dejaba solo una semana para participar, cree que es probable que el problema fuera “fundamental” y ocurriera igual si se repitiera con una muestra de caras mayor. “Aunque sospecho que con ese análisis más extenso la diferencia sería menos pronunciada o que los patrones serían menos claros”, aclara.
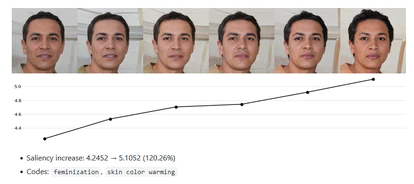
El concurso fue una especie de análisis post mortem del algoritmo. Twitter lo había eliminado en mayo y lo había sustituido por una opción manual: ahora cada usuario puede recortar la parte que quiere que se vea de la imagen que cuelga. “Es una buena opción”, cree Kulynych. La supresión del algoritmo solo elimina un pequeño problema. En el fondo, este algoritmo no era crucial: solo decidía qué partes de una foto grande mostrar. En investigaciones anteriores, algunas hechas con su tutora de tesis, la ingeniera española Carmela Troncoso, Kulynych ha analizado el impacto de otros algoritmos más importantes para las grandes tecnológicas: aquellos algoritmos esenciales que deciden qué vemos en Twitter, YouTube, Amazon o Airbnb. ¿Qué comportamientos pueden estar promoviendo en favor de los beneficios de estas empresas?
Ese tipo de algoritmos no se ponen de momento a disposición de investigadores externos para ver si hay sesgos o errores, dice Kulynych. Son una parte central de las tecnológicas: “Aparte de los errores, están los problemas en los algoritmos que emergen debido a la estructura de incentivos y optimización de beneficios dentro de las compañías”, dice Kulynych. “Con estos no organizan competiciones porque no son errores como tales. Solo pueden resolverse desde fuera y para ello sería necesaria la regulación para retos como la mitigación de la desinformación en redes sociales, o aumento de la gentrificación en plataformas como Airbnb. La capacidad de autorregulación de estas empresas es limitada”, añade.
La competición de Twitter para analizar su algoritmo caído en desgracia es loable, admite Kulynych, pero está por ver si es un primer paso o simplemente un caso aislado. Rumman Chowdhury, nueva directora (se incorporó en febrero) de Ética de Machine Learning de Twitter, dijo que no es sencillo abrir el algoritmo de recomendación de Twitter para que sea analizado desde fuera, pero “sería fascinante hacer una competición sobre sesgos de sistemas”.
En su discurso sobre esta competición, Chowdhury admitió la obviedad de que los sesgos de los algoritmos se basan en automatizar lo que los humanos hacemos de forma natural: “Hemos creado estos filtros porque creemos que eso es lo que es ‘bonito’, y eso termina entrenando nuestros modelos y llevándonos a estas nociones irreales de lo que significa ser atractivo”.
En una conversación previa en Twitter, empleados de la compañía ofrecieron una analogía para este concurso: se parece a las primeras recompensas que se dieron a quienes encontraban errores de seguridad en los programas informáticos hace años. Ahora un agujero de seguridad puede costar cientos de miles de euros o incluso millones si se vende a según quién: es un modo de acceder a sistemas sin ser detectado. Kulynych se ha llevado solo 3.500 dólares por su trabajo, que es una cantidad irrisoria para los niveles de Silicon Valley.
Pero quizá no quede ahí. “Al principio, los errores de seguridad se reportaban y nadie recibía nada a cambio, quizá ni se arreglaba el problema. Así nacieron las recompensas, para crear un incentivo para comunicarlos a los creadores del software y que los arreglaran”, dice Kulynych. La diferencia es que los problemas de seguridad pueden descubrirse desde fuera y el análisis del algoritmo requiere de la complicidad de la compañía, que debe abrirlo a análisis externo.
La detección del sesgo de Kulynych no fue la única. El segundo premio fue para un trabajo que también comprobaba que el algoritmo prestaba menos atención a rostros ancianos y el tercero se lo llevó otro investigador que descubrió, al comparar memes con texto, que el algoritmo prefería el lenguaje en grafías latinas respecto al árabe. Twitter dio también un premio a un investigador italiano que encontró que los emojis de piel clara también reciben mejor puntuación del algoritmo.
Puedes seguir a EL PAÍS TECNOLOGÍA en Facebook y Twitter o apuntarte aquí para recibir nuestra newsletter semanal.