La batalla de Facebook contra la desinformación nunca terminará a este ritmo, pero eso no significa que la compañía se haya rendido. Por el contrario, es solo a fuerza de la mejora constante de sus sistemas automatizados que puede mantenerse, aunque sea remotamente, libre de discursos de odio y desinformación. Director de tecnología Mike Schroepfer promocionó la última de esas mejoras hoy en una serie de publicaciones.
Los cambios se aplican a los sistemas adyacentes a la inteligencia artificial que utiliza la red social para eliminar de raíz los gustos del spam, noticias engañosas e insultos raciales, es decir, antes de que cualquiera, incluidos los moderadores de contenido de Facebook, vea esos elementos.
Una mejora está en los sistemas de análisis del lenguaje que Facebook emplea para detectar cosas como el discurso de odio. Esta es un área, explicó Schroepfer, en la que la empresa debe ser extremadamente cuidadosa. Los falsos positivos en el espacio publicitario (como que algo parece una estafa) son de bajo riesgo, pero los falsos positivos que eliminan publicaciones porque se confunden con un discurso de odio pueden ser problemas graves. Por eso es importante tener mucha confianza al tomar esa determinación.
Desafortunadamente, el discurso de odio y el contenido adyacente pueden ser muy sutiles. Incluso algo que parece indiscutiblemente racista puede invertirse o subvertirse con una sola palabra. La creación de sistemas de aprendizaje automático que reflejen la complejidad y variedad del lenguaje es una tarea que requiere cantidades cada vez mayores de recursos informáticos.
Linformer (“lineal” + “transformador”) es la nueva herramienta que Facebook creó para gestionar el creciente coste de los recursos de escanear miles de millones de publicaciones al día. Se aproxima al mecanismo de atención central de los modelos de lenguaje basados en transformadores en lugar de calcularlo exactamente, pero con pocas compensaciones en el rendimiento. (Si entendiste todo eso, te felicito).
Eso se traduce en una mejor comprensión del lenguaje pero costos de cálculo solo marginalmente más altos, lo que significa que no tienen que, digamos, usar un modelo peor para una primera ola y luego solo ejecutar el modelo costoso en elementos sospechosos.
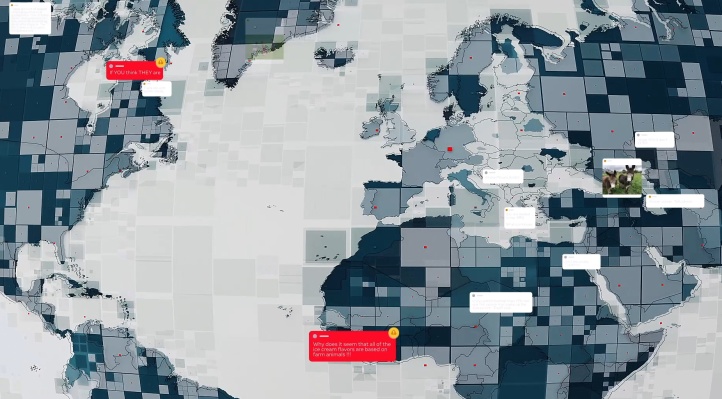
Los investigadores de la compañía también están trabajando en el problema ligeramente menos definido de comprender la interacción de texto, imágenes y texto en imágenes. Las capturas de pantalla falsas de TV y sitios web, memes y otras cosas que a menudo se encuentran en las publicaciones son increíblemente difíciles de entender para las computadoras, pero son una gran fuente de información. Además, una sola palabra modificada puede invertir completamente su significado, mientras que casi todos los detalles visuales siguen siendo los mismos.
Un ejemplo de dos casos de la misma información errónea con una apariencia visual ligeramente diferente. Consciente del izquierdo, el sistema capturó el derecho. Créditos de imagen: Facebook
Facebook está mejorando en la captura de estos en su variedad infinita, dijo Schroepfer. Todavía es muy difícil, dijo, pero han logrado grandes avances en la captura, por ejemplo, de imágenes de información errónea de COVID-19 como informes de noticias falsas que indican que las máscaras causan cáncer, incluso cuando las personas que las publican manipulan y cambian su apariencia.
La implementación y el mantenimiento de estos modelos también es compleja, y requiere un baile constante de creación de prototipos, implementación, pruebas en línea y llevar esa retroalimentación a un nuevo prototipo. Reinforcement Integrity Optimizer adopta un nuevo enfoque, monitoreando la efectividad de los nuevos modelos en el contenido en vivo, transmitiendo esa información al sistema de entrenamiento constantemente en lugar de, digamos, informes semanales.
No es fácil determinar si se puede decir que Facebook tiene éxito. Por un lado, las estadísticas que publican pintan un panorama optimista de proporciones crecientes de discursos de odio e información errónea eliminados, con millones más de discursos de odio, imágenes violentas y contenido de explotación infantil eliminados en comparación con el último trimestre.
Le pregunté a Schroepfer cómo Facebook puede rastrear o expresar su éxito o fracaso con mayor precisión, ya que los aumentos en los números podrían deberse a mecanismos mejorados para la eliminación o simplemente a volúmenes más grandes de ese contenido que se eliminan al mismo ritmo.
“La línea de base cambia todo el tiempo, por lo que debe analizar todas estas métricas juntas. Nuestra estrella del norte a largo plazo es la prevalencia ”, explicó, refiriéndose a la frecuencia real de los usuarios que encuentran un tipo de contenido determinado en lugar de si se eliminó de forma preventiva o algo así. “Si elimino mil piezas de contenido que la gente nunca vería de todos modos, no importa. Si elimino el contenido que estaba a punto de volverse viral, será un gran éxito “.
Facebook ahora incluye la prevalencia del discurso de odio en su “Informe de aplicación de las normas de la comunidad”, y lo define de la siguiente manera:
La prevalencia estima el porcentaje de veces que las personas ven contenido infractor en nuestra plataforma. Calculamos la prevalencia del discurso de odio seleccionando una muestra de contenido visto en Facebook y luego etiquetando cuánto de él viola nuestras políticas de discurso de odio. Debido a que el discurso de odio depende del idioma y el contexto cultural, enviamos estas muestras representativas a revisores de diferentes idiomas y regiones.
Y para su primera medida de esta nueva estadística:
De julio de 2020 a septiembre de 2020 fue del 0,10% al 0,11%. En otras palabras, de cada 10.000 visualizaciones de contenido en Facebook, de 10 a 11 incluían incitación al odio.
Si este número no es engañoso, implica que una de cada mil piezas de contenido en línea en este momento en Facebook califica como discurso de odio. Eso parece bastante alto. (Le pedí a Facebook un poco más de claridad sobre este número).
También se debe cuestionar la integridad de estas estimaciones: los informes de áreas devastadas por la guerra como Etiopía sugieren que son plagado de discursos de odio que se detecta, informa y elimina de forma inadecuada. Y, por supuesto, la irrupción de contenido y grupos de milicias nacionalistas y supremacistas blancos en Facebook ha sido bien documentada.
Schroepfer enfatizó que su papel está muy directamente en el lado de la “implementación” de las cosas y que las cuestiones de política, personal y otras partes importantes de las vastas operaciones de la red social están más o menos fuera de su jurisdicción. Francamente, eso es un poco decepcionante para el director de tecnología de una de las empresas más poderosas del mundo, que parece tomarse estos problemas en serio. Pero uno también se pregunta si, si él y sus equipos no hubieran sido tan asiduos en la búsqueda de soluciones técnicas como las anteriores, Facebook podría haber estado completamente cubierto de odio y falsedad en lugar de ser simplemente abatido inevitablemente.