
WellSaid Labs, cuyas herramientas crean un discurso sintético que podría confundirse con el real, ha recaudado una Serie A de $ 10 millones para hacer crecer el negocio. El motor de conversión de texto a voz casero de la compañía funciona más rápido que el tiempo real y produce clips de sonido natural de prácticamente cualquier duración, desde fragmentos rápidos hasta lecturas de horas de duración.
WellSaid salió de la incubadora del Allen Institute for AI en 2019, y su objetivo era crear voces sintéticas que no sonaran tan robóticas para fines comerciales comunes, como contenido de capacitación y marketing.
Lo logró primero al basar su solución en Tacotron, un motor de voz desarrollado por Google e investigadores académicos. Pero pronto había construido una propia que era más eficiente, dio como resultado voces más convincentes y podía producir clips de longitudes arbitrarias. Los motores del habla a menudo se disparan después de un par de oraciones, descendiendo a balbucear o perdiendo el tono, pero WellSaid’s leer la totalidad de “Frankenstein” de Mary Shelley sin contratiempos.
Las voces eran lo suficientemente buenas como para que los oyentes las calificaran como humanas o tan buenas como humanas, algo que no se puede decir realmente sobre los asistentes virtuales sospechosos habituales cuando hablan más de un puñado de palabras. No solo eso, sino que el discurso se generó considerablemente más rápido que en tiempo real, donde otras opciones de alta calidad a menudo operaban en una décima parte del tiempo real o más lento, lo que significa que tres minutos de discurso tomarían un minuto para generar por WellSaid y media hora o más por Tacotron.
Por último, el sistema permite la creación de nuevos “Avatares de voz” basados en locutores existentes, como un vocero de la empresa o un locutor de confianza. Originalmente, se necesitaban alrededor de 20 horas de audio para construir un modelo de sus peculiaridades y estilo de voz, pero ahora puede hacerlo en tan solo dos horas, dijo el CEO Matt Hocking.
La compañía está estrictamente enfocada en los negocios en este momento, lo que quiere decir que no hay una aplicación de cara al usuario para digitalizar su voz en un avatar ni nada. Hay riesgos concomitantes y no hay un modelo de negocio realista para ello, por lo que eso está fuera de la mesa por ahora.
Sin embargo, una voz tan realista podría ser de gran ayuda para las personas con discapacidades, algo que Hocking reconoce, pero admite que aún no están listos para abordar.
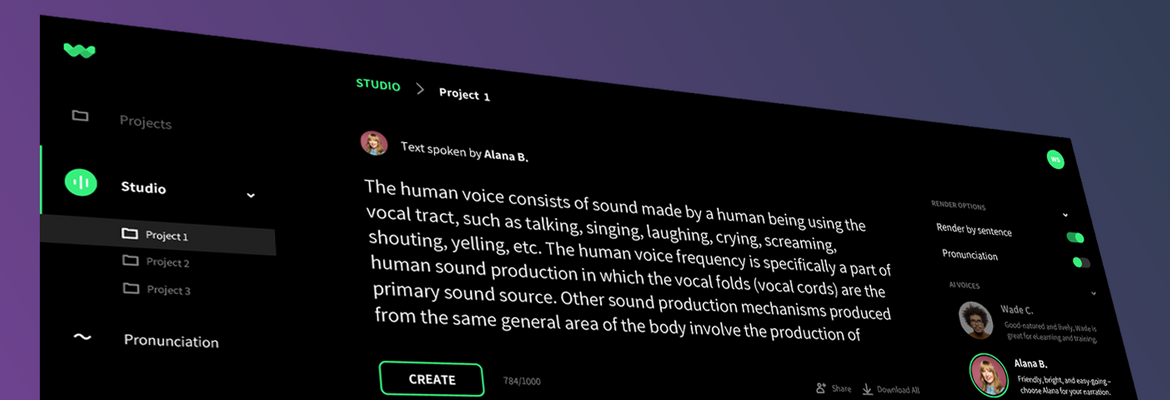
Créditos de imagen: WellSaid Labs
“Estamos comprometidos a expandir el acceso a esta tecnología para que los comunicadores no verbales, las organizaciones sin fines de lucro y otros puedan beneficiarse de ella”, dijo.
Mientras tanto, la compañía se ha expandido desde su primer mercado, videos de capacitación corporativos, a marketing, textos más extensos, productos interactivos con experiencias considerables de texto y aplicaciones. Uno espera que el talento en el que se basan estos avatares sea compensado adecuadamente por ayudar a crear una imagen digital de su voz.
La ronda de $ 10 millones con exceso de suscripción fue liderada por FUSE, con la participación del inversor habitual Voyager, Qualcomm Ventures LLC y GoodFriends, todos los cuales probablemente quedaron impresionados por el crecimiento del producto y el negocio. Las voces sintéticas han servido para un puñado de casos de uso populares, pero el contenido no ha sido muy grande, por lo que hay mucho espacio para crecer. La empresa invertirá el dinero en profundizar su oferta de productos y hacer crecer el equipo junto con ella.