Muchas cosas se dicen mejor que se leen, pero la mejor tecnología de voz parece estar reservada para los asistentes virtuales, no los lectores de pantalla o los audiolibros generados automáticamente. WellSaid desea permitir que cualquier creador use un lenguaje sintético de calidad en lugar de una voz humana, tal vez incluso una versión sintética de ellos mismos.
Ha habido una serie de avances importantes en la síntesis de voz en los últimos dos años a medida que la tecnología de redes neuronales mejora el antiguo enfoque altamente manual. Pero Google, Apple y Amazon parecen no estar dispuestos a hacer que su excelente tecnología de voz esté disponible para cualquier cosa que no sean chirridos desde su teléfono o centro de casa.
Apenas me enteré de WaveNet y, más tarde, de Tacotron, traté de comunicarme con el equipo de Google para preguntarles cuándo iban a trabajar en la producción de audiolibros de sonido natural para todo lo que se encuentra en Google Libros, o como parte de AMP. Un servicio de accesibilidad, etc. Nunca escuche de vuelta. Consideré esto como una oportunidad perdida, ya que hay muchos por ahí que necesitan este servicio.
Así que me complació escuchar que WellSaid está tomando este mercado, de alguna manera, de todas formas. La compañía es la primera en lanzar el programa de incubadora Allen Institute for AI (AI2) anunciado en 2017. ¡Se toman su tiempo!
Predicar con el ejemplo
Hablé con el CEO de los cofundadores Matt Hocking y el CTO Michael Petrochuk, quien explicó por qué crearon un sistema completamente nuevo para la síntesis de voz. El problema básico, dijeron, es que los sistemas existentes no solo dependen de una gran cantidad de anotaciones humanas para que suenen bien, sino que “suenan bien” de la misma manera cada vez. No puede simplemente darle unas pocas horas de audio y esperar que descubra cómo hacer una inflexión en las preguntas o hacer una pausa entre los elementos de la lista; mucho de esto debe explicarse en detalle. El resultado final, sin embargo, es altamente eficiente.
 “Su objetivo es hacer un modelo pequeño para barato. [i.e. computationally] que pronuncia las cosas de la misma manera cada vez. Es esta una voz perfecta “, dijo Petrochuk. “Tomamos la investigación como Tacotron y la impulsamos aún más, pero no estamos tratando de controlar el habla y aplicar esta estructura arbitraria en ella”.
“Su objetivo es hacer un modelo pequeño para barato. [i.e. computationally] que pronuncia las cosas de la misma manera cada vez. Es esta una voz perfecta “, dijo Petrochuk. “Tomamos la investigación como Tacotron y la impulsamos aún más, pero no estamos tratando de controlar el habla y aplicar esta estructura arbitraria en ella”.
“Cuando piensas en la voz humana, lo que hace natural, más o menos, son las inconsistencias”, dijo Hocking.
¿Y dónde encontrar mejor las inconsistencias que en los humanos? El equipo trabajó con un puñado de actores de voz para grabar docenas de horas de audio para alimentar el sistema. No hay necesidad de anotar el texto con un “lenguaje de marcado de voz” para designar partes de las oraciones, etc., dijo Petrochuk: “Descubrimos cómo entrenar con los datos sin procesar del audiolibro, sin tener que hacer nada por encima de eso”.
Por lo tanto, el modelo de WellSaid a menudo pronunciará la misma palabra de manera diferente, no porque un modelo de lenguaje manual cuidadosamente cuidado sugiera que lo hiciera, sino porque la persona cuya huella dactilar vocal está imitando lo hizo.
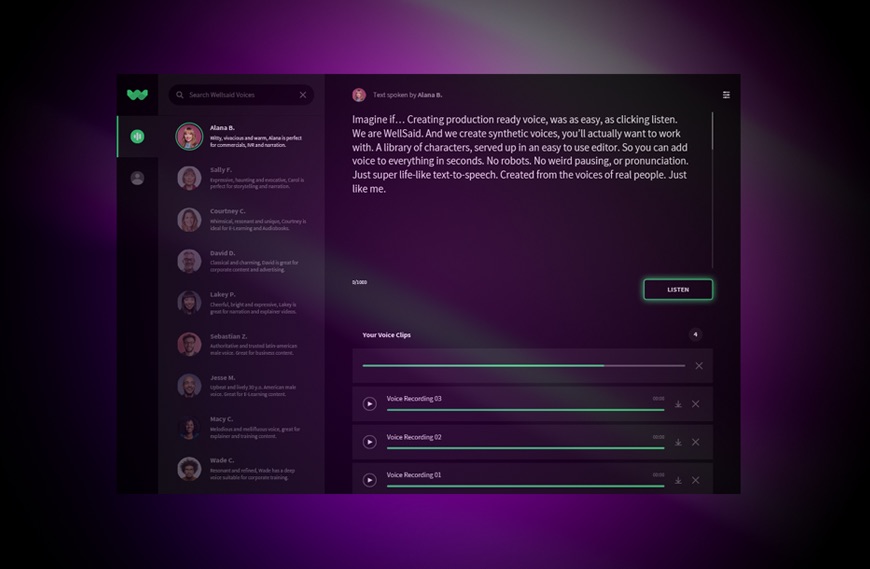 Y como hace ese ¿trabajo, exactamente? Esa pregunta parece sumergirse en la salsa secreta de WellSaid. Su modelo, como cualquier sistema de aprendizaje profundo, tiene en cuenta innumerables entradas y produce una salida, pero es más grande y de mayor alcance que otros sistemas de síntesis de voz. Cosas como la cadencia y la pronunciación no están especificadas por sus supervisores, pero se extraen del audio y se modelan en tiempo real. Suena un poco a magia, pero ese es a menudo el caso cuando se trata de investigaciones de vanguardia en IA.
Y como hace ese ¿trabajo, exactamente? Esa pregunta parece sumergirse en la salsa secreta de WellSaid. Su modelo, como cualquier sistema de aprendizaje profundo, tiene en cuenta innumerables entradas y produce una salida, pero es más grande y de mayor alcance que otros sistemas de síntesis de voz. Cosas como la cadencia y la pronunciación no están especificadas por sus supervisores, pero se extraen del audio y se modelan en tiempo real. Suena un poco a magia, pero ese es a menudo el caso cuando se trata de investigaciones de vanguardia en IA.
Se ejecuta en una CPU en tiempo real, no en un clúster de GPU en algún lugar, por lo que también se puede hacer fuera de línea. Esta es una hazaña en sí misma, ya que muchos algoritmos de síntesis de voz son bastante cargados de recursos.
Lo que importa es que la voz producida puede hablar cualquier texto de forma muy natural. Aquí está la primera parte de un artículo (por desgracia, no uno de los míos, que habría empleado más circunlocuciones melifluas) leídas por WaveNet de Google, luego por dos de las voces de WellSaid.
Los dos últimos son definitivamente un sonido más natural que el primero. En algunas frases, las voces pueden ser casi indistinguibles de sus originales, pero en la mayoría de los casos estoy seguro de que podría distinguir la voz sintética en pocas palabras.
Sin embargo, el hecho de que esté cerca es un logro. Y ciertamente puedo decir que si una de estas voces me leyera un artículo, sería de WellSaid. Naturalmente, también se puede ajustar e iterar, o se pueden aplicar efectos para manipular aún más el sonido, como con cualquier interpretación de voz. No pensaste que esas entrevistas que escuchas en NPR no están editadas, ¿verdad?
El objetivo al principio es encontrar las creatividades cuyo trabajo se mejoraría o facilitaría agregando esta herramienta a su caja de herramientas.
“Hay muchas personas que tienen esta necesidad”, explicó Hocking. “Un productor de video que no tiene el presupuesto para contratar a un actor de voz; alguien con un gran volumen de contenido que debe repetirse rápidamente; si el inglés es un segundo idioma, esto abre muchas puertas; y algunas personas simplemente no tienen voz para la radio “.
Sería bueno poder agregar voz con un clic en lugar de simplemente tener un texto de bloque y música sin royalties en un anuncio social (piense en los anuncios):
Pregunté acerca de la recepción entre los actores de voz, quienes, por supuesto, esencialmente se les pide que entrenen a sus propios reemplazos. Dijeron que los actores eran realmente positivos al respecto, pensándolo como algo así como fotografía de archivo para voz; Obtén un producto prefabricado a bajo costo y, si te gusta, paga al creador por algo real. Aunque no querían encerrarse prematuramente en futuros modelos de negocios, sí reconocieron que la participación en los ingresos con los actores de voz era una posibilidad. El pago por representaciones virtuales es algo así como un campo nuevo y en evolución.
Hoy se lanza una versión beta cerrada, que puede registrarse en el sitio de la compañía. Se lanzarán con cinco voces para comenzar, con más voces y opciones por venir a medida que el lugar de WellSaid en el mercado se aclare. Parte de ese proceso será casi con certeza la inclusión en herramientas utilizadas por personas ciegas o discapacitadas, como he esperado durante años.
Suena familiar
¿Y qué viene después de eso? Haciendo versiones sintéticas de las voces de los usuarios, por supuesto. ¡Pan comido! Pero los dos fundadores advirtieron que es una forma de alejarse por varias razones, a pesar de que es una gran posibilidad.
“En este momento estamos usando unas 20 horas de datos por persona, pero vemos un futuro en el que podemos reducirlo a 1 o 2 horas mientras mantenemos una calidad de vida superior a la voz”, dijo Petrochuk.
“Y podemos construir a partir de conjuntos de datos existentes, como donde alguien tiene un catálogo de contenido”, agregó Hocking.
El problema es que el contenido puede no ser exactamente el adecuado para entrenar el modelo de aprendizaje profundo, que, por avanzado que sea, sin duda puede ser delicado. Por supuesto, hay diales y botones que ajustar, pero dijeron que ajustar la voz es más una cuestión de agregar un discurso correctivo, tal vez tener al actor de voz leyendo un guión específico que refuerza los sonidos o las cadencias que necesitan un impulso.
Lo compararon con dirigir a tal actor en lugar de ajustar el código. Después de todo, no le dice a un actor que aumente las pausas después de las comas en un 8 por ciento o 15 milisegundos, lo que sea más largo. Es más eficiente demostrar para ellos: “Dígalo así”.
Aun así, obtener la calidad adecuada con datos de entrenamiento limitados e imperfectos es un desafío que requerirá un trabajo serio cuando el equipo decida asumirlo.
Pero como algunos de ustedes pueden haber notado, también hay algunos paralelismos con el desagradable mundo de las “fallas profundas”. Descargue una docena de podcasts o discursos y tiene suficiente material para hacer una réplica aceptable de la voz de alguien, tal vez una figura pública. Por supuesto, esto tiene una sinergia preocupante con la capacidad existente para falsificar videos y otras imágenes.
Esto no es noticia para Hocking y Petrochuk. Si trabajas en IA, este tipo de cosas es algo inevitable.
“Esta es una pregunta muy importante y la hemos considerado mucho”, dijo Petrochuk. “Venimos de AI2, donde el lema es” AI para el bien común “. Eso es algo a lo que realmente nos suscribimos, y eso nos diferencia de nuestros competidores que hicieron las voces de Barack Obama incluso antes de que tuvieran un MVP. [minimum viable product]. Vamos a observar atentamente para asegurarnos de que no se use de manera negativa, y no estamos lanzando con la capacidad de hacer una voz personalizada, porque eso permitiría que cualquiera creara una voz de cualquiera “.
El monitoreo activo es casi todo lo que se puede esperar de cualquier persona con una tecnología de inteligencia artificial potencialmente problemática, aunque están estudiando técnicas de mitigación que podrían ayudar a identificar voces sintéticas.
Con el énfasis continuo en la presentación multimedia de contenido y publicidad en lugar de estar escrito, WellSaid parece estar preparado para comenzar a jugar en un mercado en crecimiento. A medida que el producto evoluciona y mejora, es fácil visualizarlo moviéndose hacia espacios nuevos y más restringidos, como las aplicaciones de cambio de tiempo (¡podcast instantáneo con 5 voces para elegir!) E incluso tomar el control del territorio actualmente reclamado por los asistentes de voz. Suena bien para mí.