
Como ya sabrá, hay muchos datos disponibles, y algunos de ellos podrían ser bastante útiles. Pero las consideraciones de privacidad y seguridad a menudo imponen limitaciones estrictas sobre cómo se puede usar o analizar. DataFleets promete un nuevo enfoque mediante el cual se puede acceder y analizar las bases de datos de forma segura sin la posibilidad de violaciones o abusos de la privacidad, y ha recaudado una ronda inicial de $ 4.5 millones para escalarlo.
Para trabajar con datos, debe tener acceso a ellos. Si es un banco, eso significa transacciones y cuentas; si es minorista, eso significa inventarios y cadenas de suministro, etc. Hay muchos conocimientos y patrones procesables enterrados en todos esos datos, y es el trabajo de los científicos de datos y de su tipo extraerlos.
Pero y si tu hipocresía acceder a los datos? Después de todo, hay muchas industrias en las que no se aconseja o incluso es ilegal hacerlo, como en la atención médica. No se pueden tomar exactamente los registros médicos de todo un hospital, dárselos a una empresa de análisis de datos y decir “escudriñe eso y dígame si hay algo bueno”. Estos, como muchos otros conjuntos de datos, son demasiado privados o confidenciales para permitir nadie acceso sin restricciones. El más mínimo error, y mucho menos el abuso, podría tener graves repercusiones.
Sin embargo, en los últimos años han surgido algunas tecnologías que permiten algo mejor: analizar datos sin exponerlos nunca. Suena imposible, pero existen técnicas computacionales para permitir que los datos sean manipulados sin que el usuario tenga acceso a ninguno de ellos. El más utilizado se llama cifrado homomórfico, que desafortunadamente produce una enorme reducción de la eficiencia de órdenes de magnitud, y el big data se trata de eficiencia.
Aquí es donde DataFleets interviene. No ha reinventado el cifrado homomórfico, pero lo ha evitado. Utiliza un enfoque llamado aprendizaje federado, donde en lugar de traer los datos al modelo, ellos llevan el modelo a los datos.
DataFleets se integra con ambos lados de una brecha segura entre una base de datos privada y las personas que desean acceder a esos datos, actuando como un agente confiable para transferir información entre ellos sin revelar ni un solo byte de datos brutos reales.
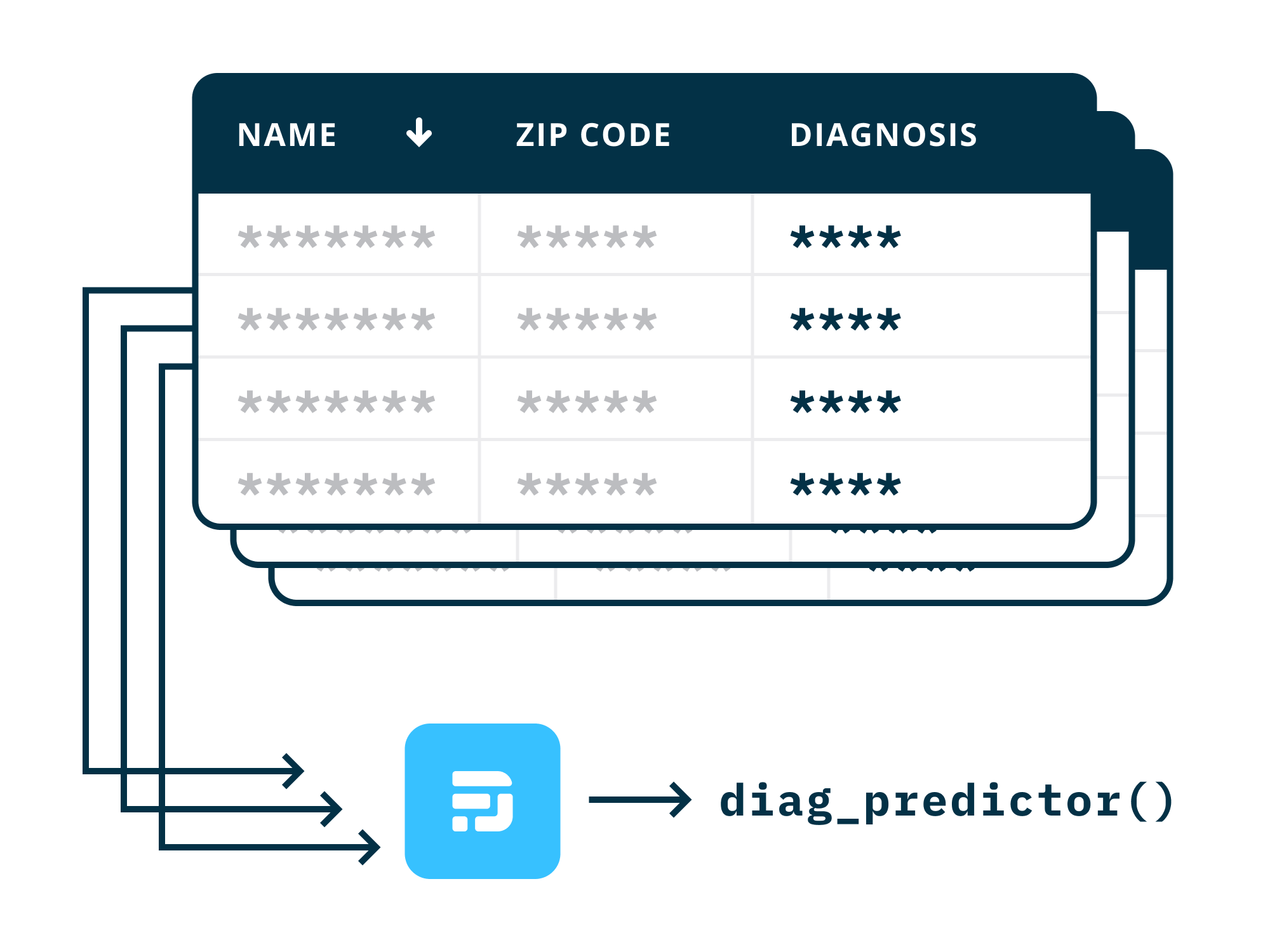
Créditos de imagen: DataFleets
He aquí un ejemplo. Supongamos que una compañía farmacéutica quiere desarrollar un modelo de aprendizaje automático que analiza el historial de un paciente y predice si tendrá efectos secundarios con un nuevo medicamento. La base de datos privada de datos de pacientes de un centro de investigación médica es lo perfecto para entrenarlo. Pero el acceso está muy restringido.
El analista de la compañía farmacéutica crea un programa de capacitación en aprendizaje automático y lo coloca en DataFleets, que contrata tanto a ellos como a la instalación. DataFleets traduce el modelo a su propio tiempo de ejecución patentado y lo distribuye a los servidores donde residen los datos médicos; dentro de ese entorno de espacio aislado, se convierte en un joven y robusto agente de ML, que cuando termina se traduce de nuevo al formato o plataforma preferidos por el analista. El analista nunca ve los datos reales, pero tiene todos los beneficios de ellos.
Captura de pantalla de la interfaz de DataFleets. Mira, son las aplicaciones las que están destinadas a ser emocionantes. Créditos de imagen: DataFleets
Es bastante simple, ¿verdad? DataFleets actúa como una especie de mensajero confiable entre las plataformas, realizando el análisis en nombre de otros y nunca reteniendo ni transfiriendo datos sensibles.
Mucha gente está estudiando el aprendizaje federado; lo difícil es construir la infraestructura para un servicio de nivel empresarial de amplio alcance. Debe cubrir una gran cantidad de casos de uso y aceptar una enorme variedad de lenguajes, plataformas y técnicas, y por supuesto hacerlo todo de forma totalmente segura.
“Nos enorgullecemos de la preparación empresarial, con la gestión de políticas, la gestión del acceso a la identidad y nuestra certificación SOC 2 pendiente”, dijo el COO y cofundador de DataFleets, Nick Elledge. “Puede construir cualquier cosa sobre DataFleets y conectar sus propias herramientas, lo que los bancos y hospitales le dirán que no era cierto en el software de privacidad anterior”.
Pero una vez que se establece el aprendizaje federado, de repente los beneficios son enormes. Por ejemplo, uno de los grandes problemas en la actualidad en la lucha contra el COVID-19 es que los hospitales, las autoridades sanitarias y otras organizaciones de todo el mundo tienen dificultades, a pesar de su voluntad, para compartir de forma segura datos relacionados con el virus.
Todos quieren compartir, pero ¿quién envía a quién qué, dónde se guarda y bajo la autoridad y responsabilidad de quién? Con los métodos antiguos, es un lío confuso. Con el cifrado homomórfico es útil pero lento. Con el aprendizaje federado, en teoría, es tan fácil como alternar el acceso de alguien.
Debido a que los datos nunca salen de su “hogar”, este enfoque es esencialmente anónimo y, por lo tanto, cumple con regulaciones como HIPAA y GDPR, otra gran ventaja. Elledge señala: “Estamos siendo utilizados por instituciones de salud líderes que reconocen que HIPAA no les brinda suficiente protección cuando ponen un conjunto de datos a disposición de terceros”.
Por supuesto, hay ejemplos menos nobles, pero no menos viables, en otras industrias: los operadores inalámbricos podrían hacer que los metadatos de los suscriptores estén disponibles sin vender a los individuos; los bancos podrían vender datos de consumidores sin violar la privacidad de nadie en particular; Los conjuntos de datos voluminosos como el video pueden quedarse donde están en lugar de ser duplicados y mantenidos a un costo elevado.
La ronda inicial de $ 4.5 millones de la compañía es aparentemente una evidencia de la confianza de una variedad de inversionistas (como lo resume Elledge): AME Cloud Ventures (Jerry Yang de Yahoo) y Morado Ventures, Lightspeed Venture Partners, Peterson Ventures, Mark Cuban, LG, Marty Chavez (presidente de la junta de supervisores de Harvard), el fondo Stanford-StartX y tres fundadores unicornio (Rappi, Quora y Lucid).
Con solo 11 empleados a tiempo completo, DataFleets parece estar haciendo mucho con muy poco, y la ronda inicial debería permitir un rápido escalado y maduración de su producto estrella. “Tuvimos que rechazar o posponer la demanda de nuevos clientes para enfocarnos en nuestro trabajo con nuestros clientes faro”, dijo Elledge. Contratarán ingenieros en los EE. UU. Y Europa para ayudar a lanzar el producto de autoservicio planeado el próximo año.
“Estamos pasando de una economía de propiedad de datos a una economía de acceso a datos, donde la información puede ser útil sin transferir la propiedad”, dijo Elledge. Si la apuesta de su empresa está en el objetivo, es probable que el aprendizaje federado sea una gran parte de eso en el futuro.