Comprender qué hace que algo sea ofensivo o hiriente es lo suficientemente difícil como para que muchas personas no puedan entenderlo, y mucho menos los sistemas de IA. Y las personas de color con frecuencia quedan fuera de los conjuntos de entrenamiento de IA. Así que no sorprende que Jigsaw generado por Alphabet/Google logre tropezar con estos dos problemas a la vez, señalando la jerga utilizada por los estadounidenses negros como tóxica.
Para ser claros, el estudio no se trataba específicamente de evaluar el algoritmo de detección del discurso de odio de la empresa, que ha enfrentado problemas anteriormente. En cambio, se cita como un intento contemporáneo de diseccionar computacionalmente el habla y asignar un “puntaje de toxicidad”, y parece fallar de una manera que indica un sesgo contra los patrones de habla de los negros estadounidenses.
Los investigadores, en la Universidad de Washington, estaban interesados en la idea de que las bases de datos de discurso de odio actualmente disponibles podrían tener sesgos raciales incorporados, como muchos otros conjuntos de datos que sufrieron la falta de prácticas inclusivas durante la formación.
Examinaron un puñado de tales bases de datos, esencialmente miles de tweets anotados por personas como “odiosos”, “ofensivos”, “abusivos”, etc. Estas bases de datos también se analizaron para encontrar un idioma fuertemente asociado con el inglés afroamericano o el inglés alineado con los blancos.
La combinación de estos dos conjuntos básicamente les permitió ver si la lengua vernácula blanca o negra tenía una mayor o menor probabilidad de ser etiquetada como ofensiva. Y he aquí que era mucho más probable que el inglés alineado con los negros fuera etiquetado como ofensivo.
Para ambos conjuntos de datos, descubrimos fuertes asociaciones entre el dialecto AAE inferido y varias categorías de discurso de odio, específicamente la etiqueta “ofensiva” de DWMW 17 (r = 0.42) y la etiqueta “abusiva” de FDCL 18 (r = 0.35), proporcionando evidencia de que El sesgo basado en el dialecto está presente en estos corpus.
El experimento continuó con los investigadores obteniendo sus propias anotaciones para los tweets y descubrieron que aparecían sesgos similares. Pero al “preparar” a los anotadores con el conocimiento de que la persona que tuiteaba probablemente era negra o usaba un inglés alineado con negro, la probabilidad de que etiquetaran un tuit como ofensivo se redujo considerablemente.
Ejemplos de control, preparación de dialectos y preparación de razas para anotadores
Esto no quiere decir necesariamente que los anotadores sean todos racistas ni nada por el estilo. Pero el trabajo de determinar qué es y qué no es ofensivo es complejo desde el punto de vista social y lingüístico, y obviamente el conocimiento de la identidad del hablante es importante en algunos casos, especialmente en los casos en que los términos que alguna vez se usaron burlonamente para referirse a esa identidad han sido reclamados.
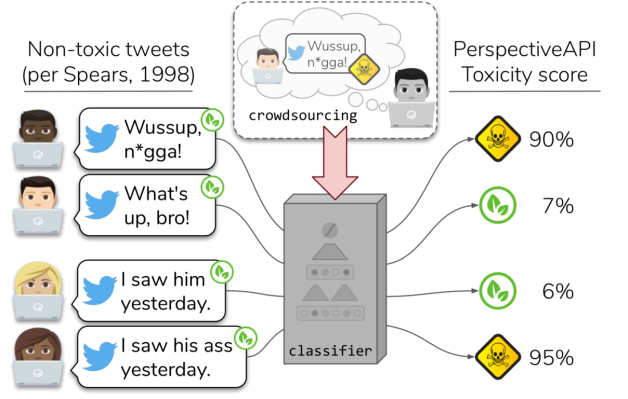
¿Qué tiene que ver todo esto con Alphabet, Jigsaw o Google? Bueno, Jigsaw es una empresa creada a partir de Alphabet, que todos conocemos como Google por otro nombre, con la intención de ayudar a moderar las discusiones en línea mediante la detección automática (entre otras cosas) del discurso ofensivo. Su API Perspective permite a las personas ingresar un fragmento de texto y recibir un “puntaje de toxicidad”.
Como parte del experimento, los investigadores enviaron a Perspective un montón de tuits en cuestión. Lo que vieron fueron “correlaciones entre dialectos/grupos en nuestros conjuntos de datos y las puntuaciones de toxicidad de Perspective. Todas las correlaciones son significativas, lo que indica un posible sesgo racial para todos los conjuntos de datos”.
Gráfico que muestra que el inglés afroamericano (AAE) tenía más probabilidades de ser etiquetado como tóxico por la API Perspectiva de Alphabet
Básicamente, descubrieron que era mucho más probable que Perspective etiquetara el discurso negro como tóxico y el discurso blanco de otra manera. Recuerde, este no es un modelo elaborado en la parte posterior de unos pocos miles de tweets, es un intento de un producto de moderación comercial.
Como esta comparación no era el objetivo principal de la investigación, sino más bien un subproducto, no debe tomarse como una especie de eliminación masiva del trabajo de Jigsaw. Por otro lado, las diferencias mostradas son muy significativas y bastante acordes con el resto de hallazgos del equipo. Como mínimo es, al igual que con los otros conjuntos de datos evaluados, una señal de que los procesos involucrados en su creación necesitan ser reevaluados.
Le pedí al autor principal del artículo, Maarten Sap, un poco más de información sobre esto y recibí una respuesta amable:
De hecho, la API de perspectiva no está destinada a ser el centro de nuestro trabajo. En cambio, encontramos un sesgo generalizado en una variedad de conjuntos de datos de detección del discurso de odio, que si entrena modelos de aprendizaje automático en ellos, esos modelos estarán sesgados contra el inglés afroamericano y los tweets de los afroamericanos. Como vemos en nuestro experimento controlado, es probable que haya algo en el contexto faltante en el que se produjo el tuit que hace que los anotadores asuman “lo peor”. Debido a que se trata de una anotación y un problema de sesgo humano, es probable que nuestros hallazgos también se apliquen a PerspectiveAPI, pero dado que no sabemos exactamente cuáles son sus datos de entrenamiento o su modelo, solo podemos observar el comportamiento de la API.
Teniendo en cuenta la evidencia de sesgo no solo en un producto que se dirige al mercado, sino también en los conjuntos de datos en los que uno podría basar un nuevo sistema, Sap sugirió que podríamos estar saltando el arma en todo este asunto de la detección automática del discurso de odio.
“Tenemos una comprensión muy limitada de los mecanismos de ofensa y cómo se relaciona con la identidad demográfica o grupal de los oradores, oyentes o anotadores y, sin embargo, estamos avanzando a toda máquina con el modelado computacional como si supiéramos cómo crear un estándar de oro. conjunto de datos”, me escribió en su correo electrónico. “Creo que ahora es el momento adecuado para comenzar a asociarnos con politólogos, psicólogos sociales y otros científicos sociales que nos ayudarán a dar sentido al comportamiento de discurso de odio existente”.
Este artículo ha sido actualizado con el comentario anterior del autor del estudio. Puede leer el documento completo, que se presentó en las Actas de la Asociación de Lingüística Computacional en Florencia, a continuación:
El riesgo de sesgo racial en la detección del discurso de odio por TechCrunch en Scribd